PArADISE: Wie Big Data im Internet der Dinge analysiert werden kann, ohne die Privatsphäre zu verletzen
Smart Metering, Internetüberwachung, Bewegungsprofile, biometrische Datenbanken, Vorratsdatenspeicherung: In der digitalen Welt werden stetig mehr Informationen über uns und unsere Umwelt gesammelt. Dabei werden unter Umständen auch Angaben über unsere persönlichen und sachlichen Verhältnisse erfasst, ohne dass wir unsere Zustimmung erteilt haben. Mit persönlichen Daten sind nicht nur Informationen zu unserem Namen oder Geburtstag zu verstehen, sondern auch Angaben zu unserem Gesundheitszustand, unseren politischen und ethischen Ansichten und zu unseren Vermögensverhältnissen.
Während das Recht auf informationelle Selbstbestimmung durch verschiedene Gesetze, wie dem Bundesdatenschutzgesetz und dem Strafgesetzbuch, gefestigt ist, existieren in der technologischen Umsetzung erhebliche Risiken. Bei der automatisierten Erhebung, Verarbeitung und Nutzung personenbezogener Daten kann in bestehenden Informationssystemen nicht garantiert werden, dass sensible Daten erkannt werden und ob deren Nutzung verhältnismäßig und mit Einwilligung des betroffenen Nutzers geschieht.
Leider geht der Trend bei smarten Systemen immer mehr dahin, die Daten fast vollständig in die Cloud zu übertragen und beim Anbieter des Systems dann ungeschützt mit Big-Data-Analytics-Methoden zu sezieren. Die Privatheitsansprüche des Nutzers werden nur dahingehend beruhigt, dass die Daten angeblich nur zum Besten des Nutzers ausgewertet werden sollen, beziehungsweise dass die Auswertung der detaillierten Nutzungsdaten ausschließlich der Verbesserung des Systems dient.
Dieses ehrenhafte Ziel mag man verschiedenen Systemanbietern nun aber nicht so recht glauben: warum müssen smarte Fernseher mit HbbTV und Spracheingabe alle aufgezeichneten Kommandos zum Hersteller übertragen? Warum müssen alle im Kinderzimmer aufgezeichneten Dialoge eines Kindes mit einer Spielzeugpuppe namens Hello zum Anbieter übertragen werden? Und selbst Anbieter von AAL-Systemen wie Teppichen mit Sensoren zur Sturzerkennung verzichten auf jegliche lokale Intelligenz und übertragen die Sensorinformationen komplett zum Hersteller, um sie dort auszuwerten.
Aufgrund der Big-Data = Big-Brother-, NSA- und Snowden-Diskussion wäre es dagegen für deutsche Hersteller ein Leichtes, smarte Systeme zu verkaufen und damit zu werben, dass ihre Systeme systemimmanent die Privatheit gewährleisten, weil sie eben konstruktionsbedingt nur die für die definierte Zielsetzung des smarten Systems nötigen Daten aus der Privatsphäre des Nutzers (Wohnung, Auto, mobiles Gerät wie Smartphone) heraustransportieren.
Das PArADISE-Framework soll es daher Forschern und Entwicklern ermöglichen, solche smarten, aber privatsphäre-sichernden Systeme zu konstruieren.
Der PArADISE-Anfrageprozessor
Wir entwickeln ein modulares Framework namens Privacy-aware Assistive Distributed Information System Environment (PArADISE), um Forscher, Anwendungsentwickler und Nutzer bei der Umsetzung datenschutzfreundlicher Informationssysteme zu unterstützen. Es ermöglicht die einfache Integration von Datenschutzmechanismen und komplexen Analysefunktionen.
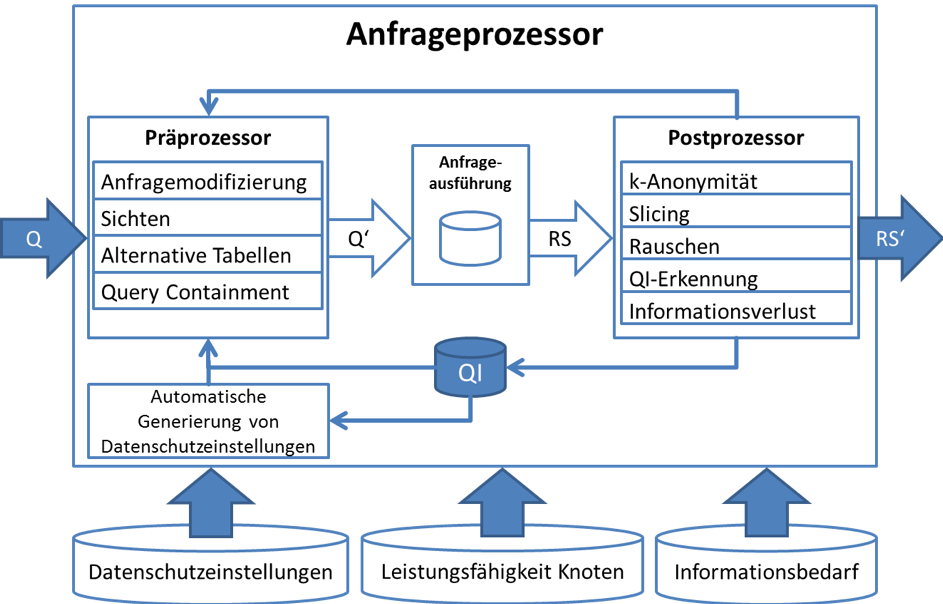
Die Architektur des PArADISE-Frameworks ist in der u.a. Abbildung dargestellt. Das Framework ist vorwiegend in Java implementiert, greift aber auch auf SQL zurück, um einige Datenschutzaspekte direkt in Datenbanksystemen auszuführen. Mögliche Ansatzpunkte stellen dabei das Umformen der Anfragen und der Ergebnisrelation sowie das Ausnutzen von Sichtenkonzepten dar.
Der Kern des Frameworks bildet der Anfrageprozessor, der aus vier Hauptkomponenten besteht:
- Der Präprozessor ermöglicht die Analyse und die Umschreibung von Datenbankanfragen.
- Bei der Anfrageausführung wird entschieden, ob die Anfrage direkt auf dem aktuellen Netzwerkknoten beantwortet und anonymisiert wird oder an einen sensornäheren Knoten weitergeleitet wird.
- Im Postprozessor wird die Anonymisierung des Anfrageergebnisses unter Berücksichtigung verschiedener Qualitäts- und Datenschutzkriterien realisiert. Es werden dazu verschiedene Datenschutzmetriken und -algorithmen bereitgestellt.
- Das Modul für die automatische Generierung von Datenschutzeinstellungen betrachtet bestehende Datenschutzrichtlinien von Nutzern und passt sie an neue Geräte und veränderte Anforderungen an.
Die PArADISE-Anfrageverteilung: Poodle
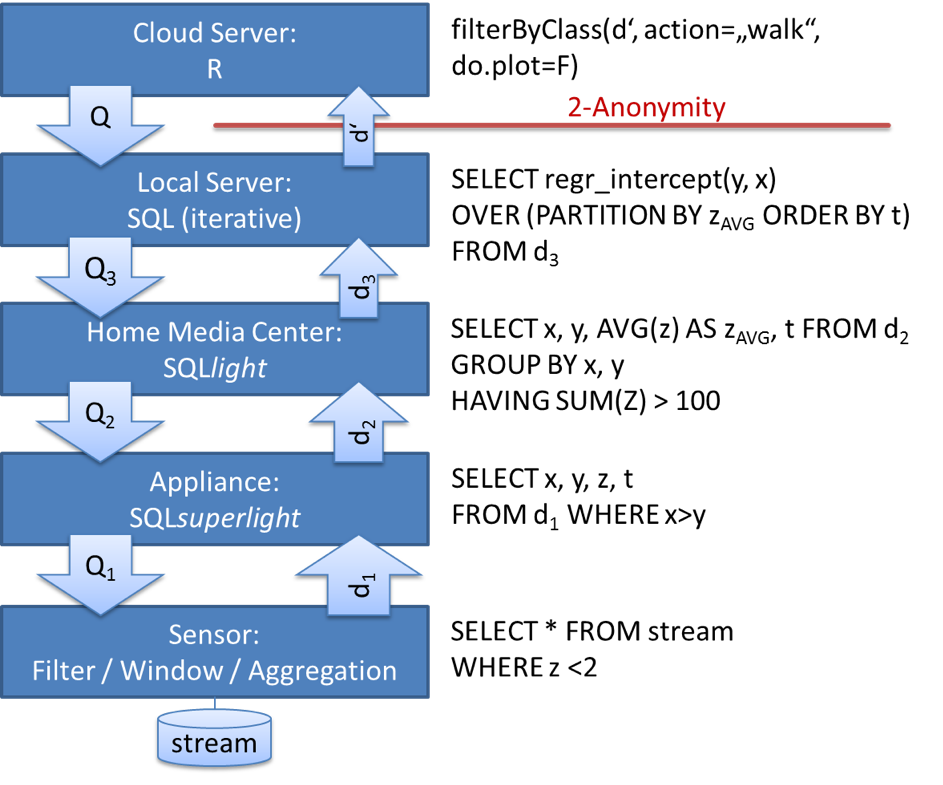
In smarten Umgebungen bzw. Assistenzsystemen werden Auswertungen an zentraler Stelle berechnet, die Daten für die Auswertung sind aber in der Regel auf mehrere Datenbanken verteilt. Für die Umsetzung wird eine Datenbankanfrage Q an die Datenbank d gesendet, welche den gesamten gespeicherten Sensordatenbestand der Umgebung integriert.
Das Ergebnis der Anfrage Q wird benötigt, um eine bestimmte Aktivitäts- und Intentionserkennungen durchzuführen. Die Datenquellen sind Sensoren, welche in unserer Umgebung, beispielsweise in unserer Wohnung bzw. im Büro, platziert wurden. Wir werden im Folgenden das Szenario Wohnung betrachten.
Stellen wir uns vor, wir hätten für unsere Wohnung einen umfassenden Assistenz-Service bei der Firma Poodle bestellt. Von Poodle erwarten wir nun bestimmte Dienste, wie eine automatisierte Problemerkennung (etwa eine Sturzerkennung). Um diese Dienste anbieten zu können, muss der Cloud-Server von Poodle nun diverse Anfragen (wie das oben genannte Q) an die Sensordatenmenge d unserer Wohnung stellen dürfen.
Anstatt die Daten d an den Cloud-Server von Poodle, welcher die Anfrage stellt, zu übertragen, werden maximale Anteile von Q so nahe wie möglich am Sensor ausgewertet. Wie in u.a. Abbildung zu sehen, wird Q(d) nicht in der Cloud ausgeführt, sondern die maximale Teilanfrage Qj auf den nächstgelegenen Knoten in der Anfragekette übertragen, im Beispiel auf einen Computer, der sich in unserer Wohnung befindet. Während Q einen in R und SQL implementierten, iterativen Lernalgorithmus ausführt und Qj eine komplexe, rekursive SQL-Anfrage, können die untersten Knoten in der Verarbeitungskette (in unserem Anwendungsszenario: Sensoren) nur einfache Filter- und Selektionsbedingungen ausführen sowie einfache Aggregationen über die zuletzt generierten Werte (Windowfunktionen, z.B. den Durchschnitt der letzten Minute) berechnen. Jeder Rechenknoten überträgt das Ergebnis dj der Anfrage Q(d) an den Knoten, welcher die Anfrage gesendet hat. Nach der Anonymisierung verlassen die modifizierten Daten d' unsere Umgebung, enthalten jedoch nur einen kleinen, aber für die ursprüngliche Anfrage Q ausreichenden, Bruchteil der Originaldaten. Poodle ist nun in der Lage, mit dem Ergebnis die benötigte Aktivitätserkennung (etwa Sturzerkennung) durchzuführen, allerdings sind über dieses Ziel hinausgehende Auswertungen unserer Daten deutlich erschwert worden.