PArADISE-Langzeit-Rahmenprojekt
Langfristig entwickeln entwickeln wir das PArADISE-Framework (Privacy-aware assistive distributed information system environment). In diesem Rahmen wollen wir die Entwickler von assistiven Systemen in drei Entwicklungsphasen unterstützen. In u.a. Abbildung zeigen wir diese Phasen als Entwicklung (links), Daten- und Dimensionsreduktion (in der Mitte) und Nutzung (rechts):
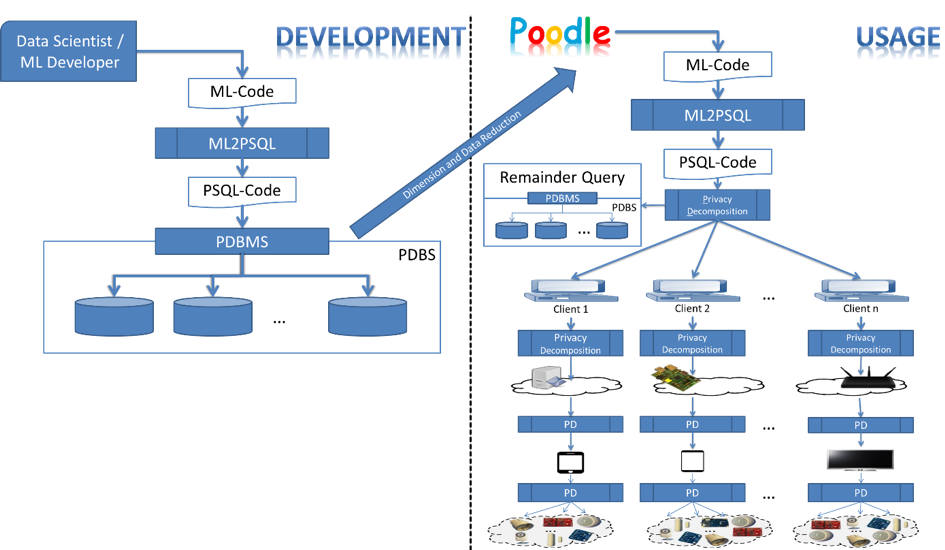
- Entwicklung: Machine-Learning-(ML-)Entwickler und Datenwissenschaftler versuchen, Benutzeraktivitäten zu erkennen und vorherzusagen, indem sie Daten von einer kleinen Anzahl von Testpersonen verwenden, Sensordaten für einen kurzen Zeitraum (vielleicht einige Wochen) sammeln, diese Sensordaten mit Aktivitätsinformationen versehen und dann versuchen, die Aktivitätsmodelle mit Hilfe von ML-Algorithmen zu lernen. Diesen Teil des Projektes nennen wir PaMeLA.
- Daten- und Dimensionsreduktion: In der Entwicklungsphase haben wir eine kleine Anzahl von Probanden, aber eine große Anzahl von Sensoren und eine hohe Frequenz in den Sensordaten. Nachdem wir die Aktivitäts- und Intentionsmodelle abgeleitet haben, müssen wir die Dimensionen der Daten (z.B. die Anzahl der auszuwertenden Sensoren) und der Daten selbst (z.B. Messung und Übertragung von Sensordaten jede Minute statt jede Millisekunde) reduzieren. Um die wichtigsten Dimensionen und Daten abzuleiten, adaptieren wir bekannte Techniken der Data Provenance und der Datenreduktion.
- Verwendung: Wenn wir das Assistenzsystem anschließend für eine große Anzahl von Clients (Millionen von Clients mit Milliarden von Sensoren) mit dem reduzierten Satz von Sensordaten verwenden, wollen wir die SQL-Anfragen zerlegen, die die Aktivitäten und Intentionen der Benutzer erkennen. Diese Anfrage-Zerlegung zielt auf eine bessere Performance ab, da die Anfrage vertikal so nah wie möglich an die Datenquellen (die Sensoren) verschoben wird. Noch wichtiger ist, dass die Zerlegung der Abfrage zu einer besseren Privatsphäre für den Benutzer der unterstützenden Systeme führt, da die meisten der ursprünglichen Sensordaten nicht seine persönliche Umgebung, seine Wohnung oder sein Auto verlassen dürfen. Lediglich eine Restabfrage, der Teil der Abfrage, der nicht auf die Clients und Sensoren verschoben werden kann, muss auf den großen Cluster-Computern des Anbieters des Assistenzsystems ausgewertet werden. Für die Zerlegung der Abfrage passen wir die Techniken des Query Containment und das Prinzip des Answering Queries using Views (AQuV) an. Dieser Teil des Projektes stellt den PArADISE-Kern dar, den wir auch nach dem Hauptszenario Poodle nennen.
Das PaMeLA-Projekt wird hier näher beschrieben, das PArADISE-Poodle-Projekt hier.
Dennis Marten und Andreas Heuer: Machine Learning on Large Databases: Transforming Hidden Markov Models to SQL Statements. Open Journal of Databases (OJDB), 4 (1). Seiten 22-42.
Hannes Grunert und Andreas Heuer: Rewriting Complex Queries from Cloud to Fog under Capability Constraints to Protect the Users' Privacy. Open Journal of Internet Of Things (OJIOT), 3 (1). Seiten 31-45. ISSN 2364-710, 2017
Johannes Goltz, Hannes Grunert und Andreas Heuer: De-Anonymisierungsverfahren: Kategorisierung und Anwendung für Datenbankanfragen (De-Anonymization: Categorization and Use-Cases for Database Queries). In: Lernen, Wissen, Daten, Analysen (LWDA) Conference Proceedings, Rostock, Germany, September 11-13, 2017
Hannes Grunert, Andreas Heuer: Datenschutz im PArADISE, in: Datenbank-Spektrum, Springer, Band 16, Heft 2, Seiten 107-117, 2016
Hannes Grunert, Andreas Heuer: Privacy Protection through Query Rewriting in Smart Environments, in: 19th International Conference on Extending Database Technology, EDBT 2016, Bordeaux, France, March 15-16, 2016, Seiten 708-709, 2016
Hannes Grunert, Martin Kasparick, Björn Butzin, Andreas Heuer, Dirk Timmermann: From Cloud to Fog and Sunny Sensors, in: Proceedings of the Conference "Lernen, Wissen, Daten, Analysen", Potsdam, Germany, September 12-14, 2016., CEUR Workshop Proceedings, Band 1670, CEUR-WS.org, Seiten 83-88, 2016
Dennis Marten, Andreas Heuer: Transparente Datenbankunterstützung für Analysen auf Big Data, in: Proceedings of the 27th GI-Workshop Grundlagen von Datenbanken, Gommern, Germany, May 26-29, 2015., Seiten 36-41, 2015
Dennis Marten, Andreas Heuer: A Framework for Self-managing Database Support and Parallel Computing for Assistive Systems, in: Proceedings of the 8th International Conference on PErvasive Technologies Related to Assistive Environments, ACM, 2015